Riddler Haircuts
Feb 28, 2020
Introduction
This week's Riddler asks us to estimate how long it takes to get a haircut with our favorite barber. Rather than scheduling an appointment, we roll the dice and hope we won't have to wait too long if we drop by unannounced. How long exactly? We'll use probability distributions and monte carlo simulation to estimate our idle time.
At your local barbershop, there are always four barbers working simultaneously. Each haircut takes exactly 15 minutes, and there’s almost always one or more customers waiting their turn on a first-come, first-served basis.Being a regular, you prefer to get your hair cut by the owner, Tiffany. If one of the other three chairs opens up, and it’s your turn, you’ll say, “No thanks, I’m waiting for Tiffany.” The person behind you in line will then be offered the open chair, and you’ll remain at the front of the line until Tiffany is available.
Unfortunately, you’re not alone in requesting Tiffany — a quarter of the other customers will hold out for Tiffany, while no one will hold out for any of the other barbers.
One Friday morning, you arrive at the barber shop to see that all four barbers are cutting hair, and there is one customer waiting. You have no idea how far along any of the barbers is in their haircuts, and you don’t know whether or not the customer in line will hold out for Tiffany.
What is the expected wait time for getting a haircut from Tiffany?
Solution
Our average wait time is just a bit longer than 14 minutes.
Methodology
I solved this problem in two ways: first by running a simulation, then by writing the probability density function analytically. Fortunately, my two results converged, and they both resulted in the final value of 14.0625. The simulation code is highly efficient, allowing you to run tens of millions of scenarios nearly instantly.
>>> trials = 10_000_000
>>> results = model(trials)
>>> print(results)
14.06276349572674
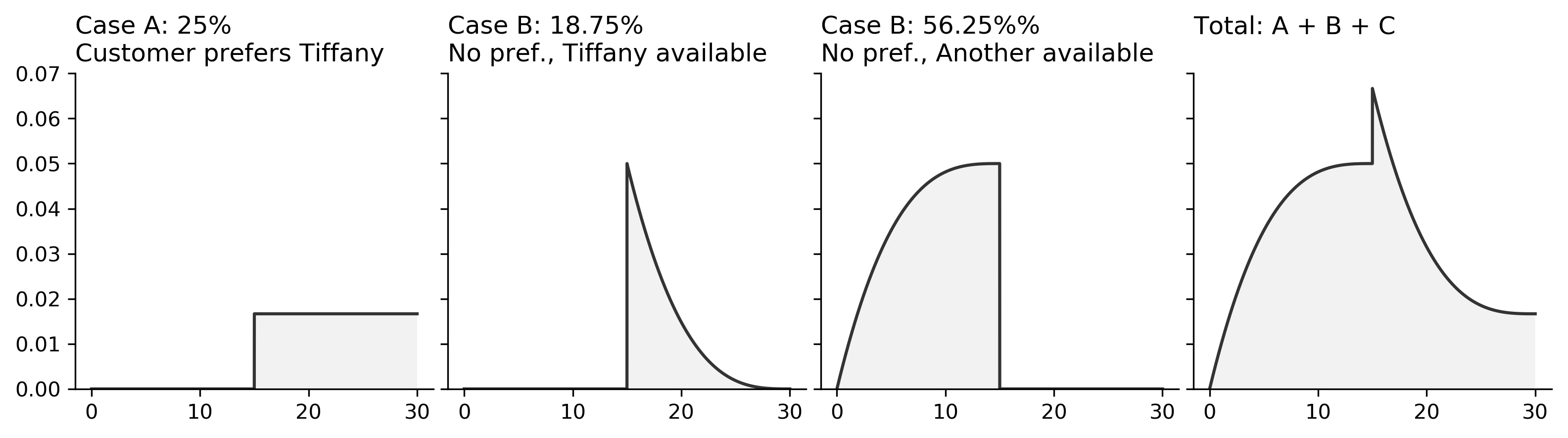
The analytical work, on the other hand, was much more complicated, and, forgive me, but I'll leave my scrap work out of this week's writeup. Instead, I'll show the three components of the problem in separate charts and how they add up to a legitimate probability density function in the image below. Indeed we can use these density functions to calculate the exact value, and it was fun to see the progression of each of the three cases build up to the whole. Those three cases are:
- A - the case in which the customer ahead of us always chooses Tiffany. We must wait until she finishes the current haircut, plus an additional 15 minutes for the next customer. This occurs 25% of the time.
- B - the case in which the customer ahead of us doesn't care about the barber, but Tiffany becomes the first available. Our wait time is the same as in A, which is Tiffany's cut time plus an additional 15 minutes. This occurs 18.75% of the time, which is calculated by multiplying 75% (the likelihood that the customer ahead of us does not prefer Tiffany) and 25% (the odds that Tiffany finishes first among her three other colleagues.
- C - finally, we tackle the best-case scenario, where the customer ahead of us doesn't prefer Tiffany and is able to be served by a different barber. Therefore, we only have to wait for Tiffany to finish her current cut before we can be seated. The complicating element here is that Tiffany must not finish before any of the other barbers, which makes the probability distribution slightly more complicated to evaluate.
In any case, when we sum each of the possibilities together, we get the chart on the far right, which lets us calculate the probability of being seated within some range of times, such as "between 10 and 15 minutes" or "between 10:00 and 10:01 minutes".
Full Code
Simulation code is below. It's fast! You can run 10 million scenarios in a snap of the fingers.
import numpy as np
def model(trials: int, barbers: int = 4, haircut_time: int = 15) -> np.ndarray:
"""
Simulate a number of haircut scenarios and return an array of results,
which are the times it takes for your haircut with tiffany to begin.
This is a vectorized simulation, so calculating ten million or more
scenarios is nearly instantaneous.
"""
# simulate the time it would take each barber to finish their haircut
# we assume tiffany is listed first in the array, but it's arbitrary
haircuts = np.random.uniform(high=haircut_time, size=(trials, barbers))
# determine whether or not tiffany finishes cutting hair first
tiffany_first = haircuts.argmin(axis=1) == 0
# simulate an array representing whether or not the customer ahead of
# us prefers tiffany, which happens 25% of the time
prefers_tiffany = np.random.uniform(size=trials) < 0.25
# create an array to store the results, then go through the cases
results = np.zeros(shape=trials)
# case 1: customer ahead of us doesn't prefer tiffany AND she doesn't
# finish first, so we simply wait for her to finish before our turn
idx = (~tiffany_first) & (~prefers_tiffany)
results[idx] = haircuts[idx, 0]
# case 2: all other cases require us to wait for tiffany to finish
# her existing haircut, then another 15 minutes, either because the
# customer ahead prefers her, or because she finished first
results[~idx] = haircuts[~idx, 0] + haircut_time
return results
if __name__ == "__main__"
results = model(10_000_000)
print(results.mean())
And lastly, the code to generate the probability density functions and plot, which were coded somewhat manually based on my calculations.
from matplotlib import pyplot as plt
import numpy as np
def a(x):
"""
Customer ahead of us prefers Tiffany, so we wait for her
to finish her current cut plus one more before our turn.
"""
out = np.full_like(x, 1 / 15)
out[x < 15] = 0.0
return out
def b(x):
"""
Tiffany finishes first, so we have to wait for her finish
time plus the full time for another haircut ahead of us
"""
out = 4 / 15 ** 4 * (15 - (x - 15)) ** 3
out[x < 15] = 0.0
return out
def c(x):
"""
Tiffany doesn't finish first, and the customer ahead of us
didn't prefer her, so we can be served as soon as she's done.
"""
out = 4 / 45 * (1 - ((15 - x) / 15) ** 3)
out[x >= 15] = 0.0
return out
def d(x):
"""Sum the individual components by weight"""
return a(x) * 0.25 + b(x) * 0.1875 + c(x) * 0.5625
fig, ax = plt.subplots(ncols=4, sharex=True, sharey=True, figsize=(10, 2))
plt.tight_layout(pad=-1.5)
ax[0].set_title("Case A: 25%\nCustomer prefers Tiffany", loc="left")
ax[1].set_title("Case B: 18.75%\nNo pref., Tiffany available", loc="left")
ax[2].set_title("Case B: 56.25%%\nNo pref., Another available", loc="left")
ax[3].set_title("Total: A + B + C\n", loc="left")
x = np.linspace(0, 30, 10001)
ax[0].plot(x, a(x) * 0.25, c='0.2')
ax[1].plot(x, b(x) * 0.1875, c='0.2')
ax[2].plot(x, c(x) * 0.5625, c='0.2')
ax[3].plot(x, d(x), c='0.2')
ax[0].fill_between(x, a(x) * 0.25, 0, facecolor="0.95")
ax[1].fill_between(x, b(x) * 0.1875, 0, facecolor="0.95")
ax[2].fill_between(x, c(x) * 0.5625, 0, facecolor="0.95")
ax[3].fill_between(x, d(x), 0, facecolor="0.95")
for i in range(4):
ax[i].set_ylim(0, 0.07)
for s in ["top", "right"]:
ax[i].spines[s].set_visible(False)
plt.show()